HDFS的故障恢复和高可用
推荐
在线提问>>
作为分布式文件系统的HDFS,在Hadoop技术生态当中,始终是不容忽视的。HDFS的稳定性和可靠性,对于后续的数据处理环节,提供底层支持,起着至关重要的作用。今天的大数据开发分享,我们就主要来讲讲HDFS的故障恢复和高可用。

HDFS的故障恢复和高可用,是确保数据存储稳定和高效的重要举措,要讲故障恢复和高可用,我们先要了解HDFS的存储运行流程。
HDFS存储运行流程
1、HDFS读取数据
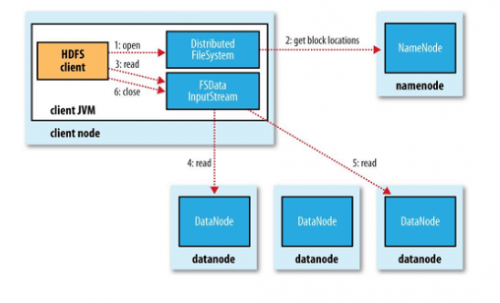
步骤:
客户端调用FileStype对象的open()方法打开希望打开的文件;
DistributedFileSystem通过RPC调用NameNode来获取起始块的位置。NameNode返回的是含有该块副本的DataNode地址(DataNode与客户端的网络拓扑排序);
DistributedFileSystem返回一个FSDataInputStram对象给客户端并读取数据;
客户端调用read()方法从DataNode读取块;
一个数据块传输到客户端完毕后,寻找下个块的最佳DataNode;
所有块读取完毕后,FSDataInputStram调用close()方法,完成数据读取。
2、HDFS数据写入
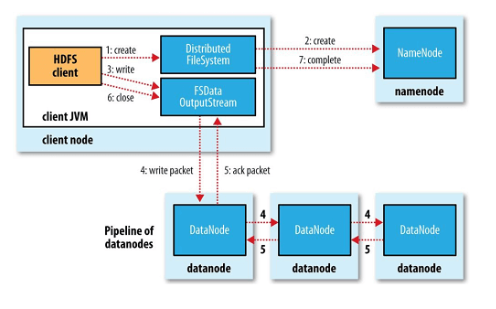
步骤:
客户端通过对DistributedFileSystem调用create()方法来新建文件;
对NameNode创建一个RPC调用,在文件系统NameSpace中新建一个文件,此时NameNode会执行各种检查以确保文件不存在及客户端的创建权限;
检查通过,DistributedFileSystem向客户端返回一个FSDataOutputStream对象,负责DataNode和NameNode之间的通信。FSDataOutputStream将数据分成一个个的数据包并写入数据队列;
FSDataOutputStream向NameNode申请保存数据块的DataNode列表,假如副本数为3,3个DataNode构成一个数据管道,队列中的数据包会依次写入管道;
接收到数据包的DataNode需要向发送者发送“确认包”,“确认队列”逆流而上直到客户端收到应答,并将数据包从数据队列中删除;
客户端调用close()完成数据的写入。
HDFS的故障恢复和高可用
1、HDFS NameNode冷备份
NameNode运行期间,HDFS的所有更新操作都记录在EditLog中,久而久之EditLog文件将变得很大。当NameNode重启时,需要先将FsImage加载到内存,然后逐条执行EditLog中的记录。当EditLog变得巨大时,会导致NameNode启动非常慢,同时由于HDFS系统处于安全模式,无法提供对外写操作,影响用户的使用。
解决方案:Secondly NameNode-用于保存NameNode中对元数据的备份,减少NameNode的启动时间,一般单独运行在一台机器中。具体实现如下:
SecondlyNameNode定义和NameNode通信,请求其停止使用EditLog,并暂时将新的更新操作记录到edit.new文件;
SecondlyNameNode通过HTTP GET方式从NameNode下载FsImage和EditLog文件到本地;
SecondlyNameNode将FsImage加载到内存,并逐条执行EditLog的记录,使FsImage保持到最新;
SecondlyNameNode通过POST方式将新的FsImage发送到NameNode;
NameNode用新的FsImage替换掉旧的FsImage文件,并将edit.new替换为正式的EditLog,此时EditLog便完成了“瘦身”。
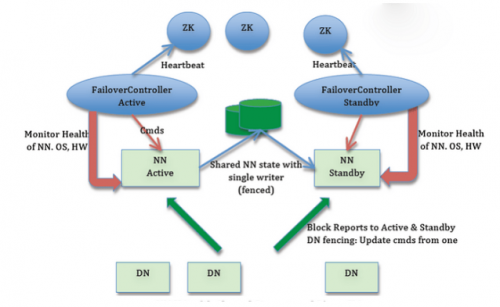
2、DataNode出错
每个DataNode定期向NameNode发送“心跳”汇报自己的健康状态;
当DataNode发生故障或者网络故障,NameNode无法接收DataNode的心跳,这些NataNode会标记为宕机,该节点的数据不可读;
DadaNode的失效会导致数据块的副本数小于最小冗余因子,NameNode会启动副本冗余复制,产生新的副本。
3、数据出错
网络原因和硬盘错误等因素会造成数据错误。
客户端读取到数据后,就采用MD5和SHA1算法对数据块进行校验,以确保读到正确的数据。
文件创建时,客户端会对每一个文件进行信息摘录并将信息存储到同一路径的隐藏文件里;客户端读取文件时,会先校验该信息文件与读取的文件,如果校验出错,便请求到另一DataNode读取数据,同时向NameNode汇报,以删除和复制这个数据块。
关于大数据开发,HDFS的故障恢复和高可用,以上就为大家做了简单的介绍了。HDFS作为Hadoop的核心组件之一,在学习阶段是需要重点掌握的,理论结合实操,才能真正掌握到家
注:本文部分文字和图片来源于网络,如有侵权,请联系删除。版权归原作者所有!此页面下方声明无效!








