大数据开发:Flink on Yarn原理
推荐
在线提问>>
在流计算越来越受到重视的大趋势下,Flink框架受到的关注和重视,可以说是与日俱增,在大数据的学习当中,Flink也成为重要的一块。今天的大数据开发分享,我们主要来讲讲,Flink on Yarn原理。

Yarn架构原理
Yarn模式在国内使用比较广泛,基本上大多数公司在生产环境中都使用过Yarn模式。
Yarn的架构原理如下图所示,最重要的角色是ResourceManager,主要用来负责整个资源的管理,Client端是负责向ResourceManager提交任务。
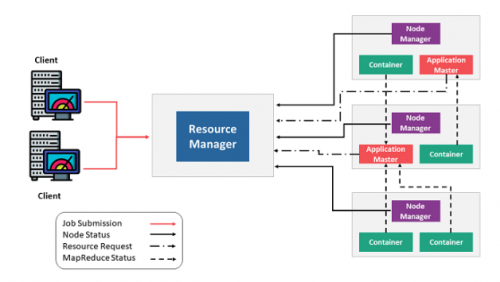
用户在Client端提交任务后会先给到Resource Manager。Resource Manager会启动Container,接着进一步启动Application Master,即对Master节点的启动。当Master节点启动之后,会向Resource Manager再重新申请资源,当Resource Manager将资源分配给Application Master之后,Application Master再将具体的Task调度起来去执行。
Yarn组件
Yarn集群中的组件包括:
ResourceManager(RM):ResourceManager(RM)负责处理客户端请求、启动/监控ApplicationMaster、监控NodeManager、资源的分配与调度,包含Scheduler和Applications Manager。
ApplicationMaster(AM):ApplicationMaster(AM)运行在Slave上,负责数据切分、申请资源和分配、任务监控和容错。
NodeManager(NM):NodeManager(NM)运行在Slave上,用于单节点资源管理、AM/RM通信以及汇报状态。
Container:Container负责对资源进行抽象,包括内存、CPU、磁盘,网络等资源。
Yarn组件运行交互
以在Yarn上运行MapReduce任务为例来讲解下Yarn架构的交互原理:
首先,用户编写MapReduce代码后,通过Client端进行任务提交。
ResourceManager在接收到客户端的请求后,会分配一个Container用来启动ApplicationMaster,并通知NodeManager在这个Container下启动ApplicationMaster。
ApplicationMaster启动后,向ResourceManager发起注册请求。接着ApplicationMaster向ResourceManager申请资源。根据获取到的资源,和相关的NodeManager通信,要求其启动程序。
一个或者多个NodeManager启动Map/Reduce Task。
NodeManager不断汇报Map/Reduce Task状态和进展给ApplicationMaster。
当所有Map/Reduce Task都完成时,ApplicationMaster向ResourceManager汇报任务完成,并注销自己。
Flink on Yarn–Per Job
Flink on Yarn中的Per Job模式是指每次提交一个任务,然后任务运行完成之后资源就会被释放。在了解了Yarn的原理之后,Per Job的流程也就比较容易理解了,具体如下:
首先Client提交Yarn App,比如JobGraph或者JARs。
接下来Yarn的ResourceManager会申请第一个Container。这个Container通过Application Master启动进程,Application Master里面运行的是Flink程序,即Flink-Yarn ResourceManager和JobManager。
最后Flink-Yarn ResourceManager向Yarn ResourceManager申请资源。当分配到资源后,启动TaskManager。TaskManager启动后向Flink-Yarn ResourceManager进行注册,注册成功后JobManager就会分配具体的任务给TaskManager开始执行。
关于大数据开发,Flink on Yarn原理,以上就为大家做了简单的介绍了。大数据在快速发展当中,相关的技术框架也在持续更新迭代,作为大数据开发者,也要能够跟得上技术趋势才行
注:本文部分文字和图片来源于网络,如有侵权,请联系删除。版权归原作者所有!此页面下方声明无效!








