HBase合并
推荐
在线提问>>
本期就给大家带来HBase的合并的小技巧。无论是在大数据开发的学习中还是其他的学习,小技巧都能够在我们的学习路上带来很多实用的帮助。

一、概述
老规矩,先来给大家复习下一些基础知识,免得又忘了。
HBase表的基本单位是Region,日常调用HBase API操作一个表时,交互的数据也会以Region的形式进行呈现。前面介绍过HBase Region拆分策略原理,一个表可以有若干个Region,本文主要介绍Region合并的一些问题和解决方法。
什么是HBase Compaction?
简单来说就是HBase将Region中的Store中的一些HFile进行合并。
二、合并原因及原理
原因:这个需要从Region的Split来说。当一个Region被不断的写数据,达到Region的Split的阀值时(由属性hbase.hregion.max.filesize来决定,默认是10GB),该Region就会被Split成两个新的Region。随着业务数据量的不断增加,Region不断的执行Split,那么Region的个数也会越来越多。
一个业务表的Region越多,在进行读写操作时,或是对该表执行Compaction操作时,此时集群的压力是很大的。这里笔者做过一个线上统计,在一个业务表的Region个数达到9000+时,每次对该表进行Compaction操作时,集群的负载便会加重。而间接的也会影响应用程序的读写,一个表的Region过大,势必整个集群的Region个数也会增加,负载均衡后,每个RegionServer承担的Region个数也会增加。
因此,这种情况是很有必要的进行Region合并的。比如,当前Region进行Split的阀值设置为30GB,那么我们可以对小于等于10GB的Region进行一次合并,减少每个业务表的Region,从而降低整个集群的Region,减缓每个RegionServer上的Region压力。
其合并原理分为三步:排序文件、合并文件、代替原文件服务。
HBase首先从待合并的文件中读出HFile中的key-value,再按照由小到大的顺序写入一个新文件(storeFile)中。这个新文件将代替所有之前的文件,对外提供服务。
在分析合并Region之前,我们先来了解一下Region的体系结构,如下图所示:
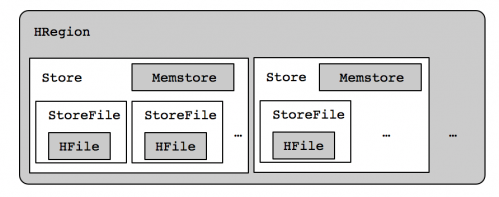
从图中可知
HRegion:一个Region可以包含多个Store;
Store:每个Store包含一个Memstore和若干个StoreFile;
StoreFile:表数据真实存储的地方,HFile是表数据在HDFS上的文件格式。
当HBase合并时,会清空以下三种数据
1.标记为删除的数据。
当我们删除数据时,HBase并没有把这些数据立即删除,而是将这些数据打了一个个标记,称为“墓碑”标记。在HBase合并时,会将这些带有墓碑标记的数据删除。
2.TTL过期数据
TTL(time to live)指数据包在网络中的时间。如果列族中设置了TTL过期时间,则在合并的过程中,发现过期的数据将被删除。
3.版本合并
若版本号超过了列族中预先设定的版本号,则将最早的一条数据删除。
如:列族设置版本号是5,当此列族第六次保存数据时,会将最早一次数据删除。
三、HBase合并分类
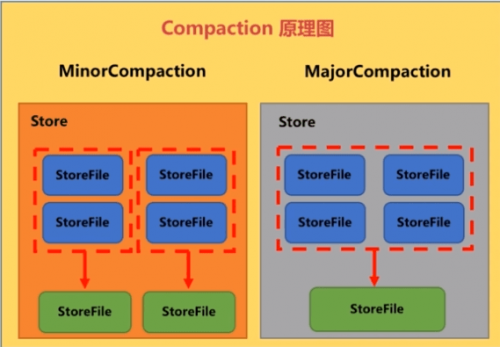
1.Minor Compaction(小合并)
小合并是指将相邻的StoreFile合并为更大的StoreFile。
2.Major Compaction(大合并)
大合并是将多个StoreFile合并为一个StoreFile。
四、合并的触发时机
(1)MEMStore Flush
内存中的数据flush刷写到硬盘上以后,会对当前Store中的文件进行判断,当数量达到阈值,则会触发Compaction。Compaction是以Store为单位进行合并的。当Flush刷写完成后,整个Region的所有Store都会执行Flush。
(2)后台线程周期性的检查
Compaction Checker线程定期检查是否触发Compaction,Checker会优先检查文件数量是否大于阈值,再判断是否满足major Compaction的条件的时间范围内,如果满足,则触发一次大合并Major Compaction。
(3)手动触发
1.由于很多业务担心MajorCompaction影响读写性能,所以选择在低峰期手动触发合并。
2.当用户修改表结构后,希望立刻生效,则手动触发合并。
3.运维人员发现硬盘空间不够,则会手动触发合并,因为删除了过期数据,腾出空间。
【免责声明】本文部分系转载,转载目的在于传递更多信息,并不代表本网赞同其观点和对其真实性负责。如涉及作品内容、版权和其它问题,请在30日内与联系我们,我们会予以更改或删除相关文章,以保证您的权益!此页面下方声明无效!









