Hadoop与Spark如何设计容错
推荐
在线提问>>
在大数据技术生态当中,分布式集群是解决大规模数据处理任务的主要解决思路,主流的几代框架,如Hadoop、Spark、Flink都是基于分布式去进行设计。而分布式系统,关于容错的问题就非常关键了。今天我们就来讲讲Hadoop与Spark是如何设计容错的?

一般来说,关于容错,最朴素的想法就是通过下面的步骤实现状态与容错:
①暂停所有数据的接收。
②每个任务处理当前已经接收的数据。
③将此时所有任务的状态进行持久化。
④恢复数据的接收和处理。
当作业出现异常时,则可以从之前持久化的地方恢复。Hadoop与Spark的容错机制就是该思想的实现。
Hadoop的任务可以分为Map任务和Reduce任务。这是两类分批次执行的任务,后者的输入依赖前者的输出。Hadoop的设计思想十分简单——当任务出现异常时,重新跑该任务即可。其实,跑成功的任务的输出,就相当于整个作业的中间结果得到了持久化。比如Reduce任务异常重跑时,就不必重跑它依赖的Map任务。
Spark的实现也是这一想法的延续。虽然Spark不是Hadoop那样的批处理,但是它仍然把一个“微批(micro batch)”当作数据处理的最小单元,整个框架实际上延续了不少批处理的思想。Spark的容错机制相当经典,用到了其RDD的血统关系(lineage)。熟悉Spark的读者应该了解“宽依赖”、“窄依赖”等概念。当RDD中的某个分区出现故障,那么只需要按照这种依赖关系重新计算即可。以复杂一些的宽依赖为例,Spark会找到其父分区,经过计算重新获取结果。
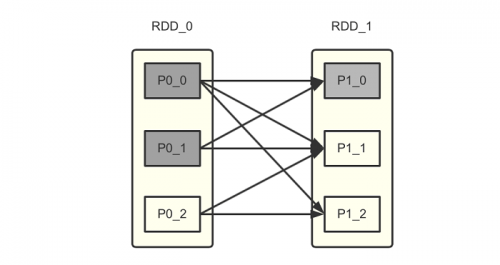
如上图所示,如果P10发生故障,则P00与P01都会重新计算,而计算P00和P01又会继续找其父分区重新计算。按照这个血缘关系来看,一直向上追溯会付出极大的代价。因此Spark提供了将分区计算结果持久化的方法。如果P00与P0_1的数据进行了持久化,那么就可以利用该结果直接恢复状态。
从以上设计可以感受到,这种实现更适合于批计算的框架中。它相当于将前一个阶段的计算结果“存档”下来,然后在任意时间后将该结果作为输入,运行下一个阶段的任务。这种实现的状态存储过程显然过于繁重,并不太适用于对“低延时”要求极高的流处理引擎。因此,Flink设计了一套完全不同的分布式轻量级实现方式,并精巧地实现了各种一致性语义。Flink我们在接下来再细讲。
关于大数据学习,Hadoop与Spark如何设计容错,以上就为大家做了大致的介绍了。Hadoop和Spark,本质上来说,都是基于批处理的思想去处理数据,自然,对于容错也是基于同样的思路。
【免责声明】本文部分系转载,转载目的在于传递更多信息,并不代表本网赞同其观点和对其真实性负责。如涉及作品内容、版权和其它问题,请在30日内与联系我们,我们会予以更改或删除相关文章,以保证您的权益!此页面下方声明无效!









